|
Xinran (Nicole) Han
I am a PhD student at Harvard University, advised by Prof. Todd Zickler.
I also work closely with Prof. Ko Nishino and have spent two wonderful summers in Kyoto.
|

|
Research
My current research interests include computer vision, generative models and multi-modal learning.
|

|
From Anyframe to Timelapse: Consistent Video Generation with Representation Alignment
Xinran (Nicole) Han, Matias Mendieta, Moein Falahatgar Preprint, 2025 (Work done during internship at Apple.) blog post We introduce derivative representation alignment (dREPA) for image-to-video generation and show it improves subject consistency and leads to better generalization across artistic styles. |

|
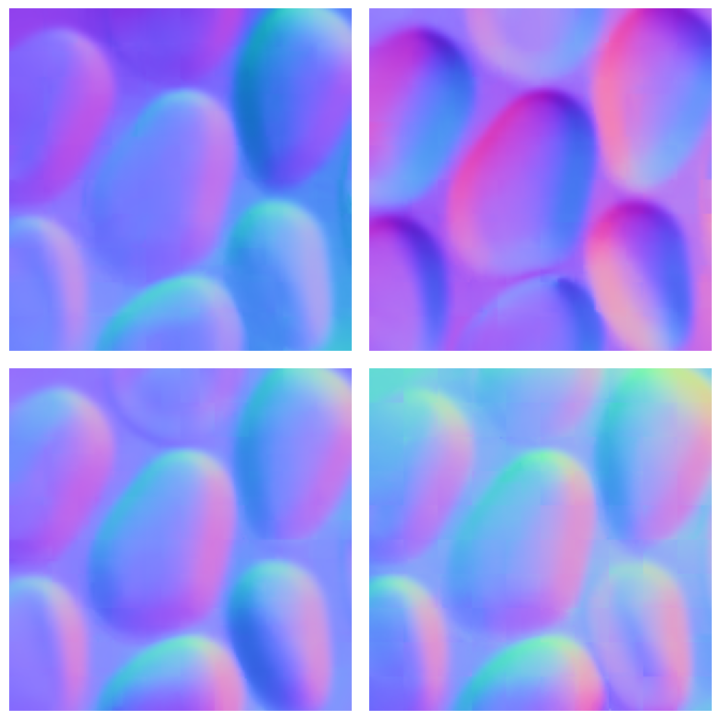
Generative Perception of Shape and Material from Differential Motion
Xinran (Nicole) Han, Ko Nishino, Todd Zickler NeurIPS, 2025 project page / paper / code We show that a novel pixel-space video diffusion model trained from scratch estimates accurate shape and material from short videos, and also produces diverse shape and material samples for ambiguous input images. |

|
Multistable Shape from Shading Emerges from Patch Diffusion
Xinran (Nicole) Han, Todd Zickler, Ko Nishino NeurIPS, 2024 (Spotlight) project page / paper / code We present a bottom-up, patch-based diffusion model for monocular shape from shading that produces multimodal outputs, similar to multistable perception in humans. |
|
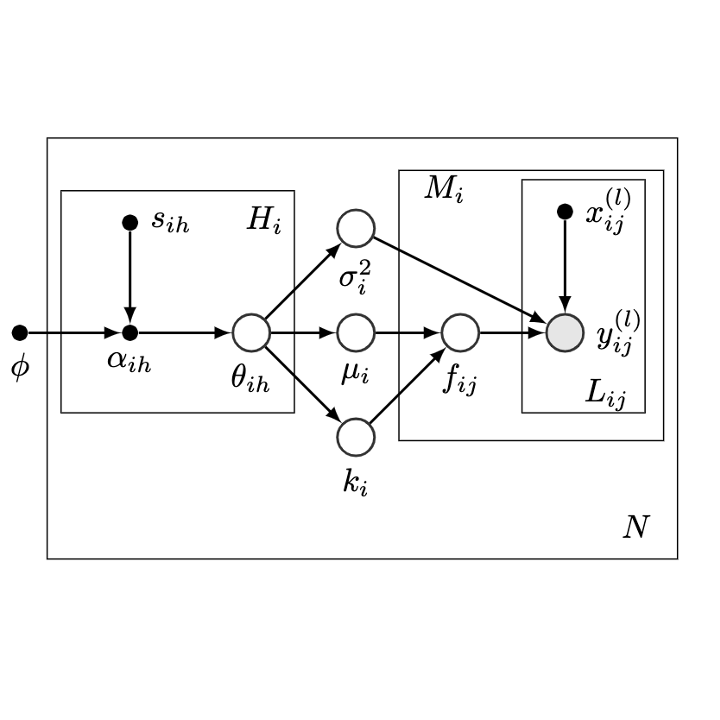
Transfer Learning for Bayesian Optimization on Heterogeneous Search Spaces
Zhou Fan, Xinran Han, Zi Wang Transactions on Machine Learning Research (TMLR), February 2024 paper We present new theoretical insight on the equivalence of multi-task and single-task learning for stationary kernels and develop MPHD for model pre-training on heterogeneous domains. |


|
Curvature Fields from Shading Fields
Xinran Han, Todd Zickler NeurIPS Workshop on Symmetry and Geometry in Neural Representations (PMLR 228), 2023 paper We present a neural model for inferring a curvature field from shading images that is invariant under lighting and texture variations, drawing on perceptual insights and mathematical derivations. |


|
Compositional Data and Task Augmentation for Instruction Following
Soham Dan* Xinran Han*, Dan Roth (* equal contribution) Findings of EMNLP, 2021 paper Auxiliary objectives and instruction augmentation improve spatial reasoning in the 'blocks world' task, especially under limited data. |


|
ForkGAN: Seeing into the Rainy Night
Ziqiang Zheng, Yang Wu, Xinran Han, Jianbo Shi ECCV, 2020 (Oral Presentation) paper / talk We introduce a task-agnostic image translation model ForkGAN that effectively disentangle domian-specific and domain-invariant information. |
MiscellaneousOutside of research, I enjoy visiting art museums, watching movies and reading about philosophy and psychology. |
|
I'm also using Jon's website template. |